

How Can a RAG Agent Handle ISO, GDPR and EU AI Act?


Compliance teams are not struggling because they lack documentation. Most enterprise organisations have more of it than they can manage. The problem is retrieval, cross-referencing, and currency. Knowing which document applies to which obligation, whether it reflects the latest framework version, and how it interacts with requirements from a completely separate regulatory regime - these are the questions that consume compliance capacity daily.
Managing ISO standards, GDPR, and the EU AI Act in parallel is no longer an edge case. For any organisation building or deploying technology in Europe, all three are live obligations. The question is no longer whether to address them simultaneously, but how to build the infrastructure to do it without doubling the size of the compliance function.
A RAG-powered agent does not make compliance simple. But it fundamentally changes the operational economics of managing it.
What Makes Multi-Framework Compliance So Difficult?
Each framework was designed independently, by different bodies, with different priorities and different vocabularies. ISO standards are built around controls, evidence, and audit cycles. GDPR is built around rights, legal bases, and accountability. The EU AI Act is built around risk classification, conformity, and transparency obligations.
Where they intersect, the overlaps are rarely mapped in either framework's official documentation. That mapping falls to the compliance team. For most organisations, that means manual reviews and a significant amount of institutional knowledge held by a small number of people. When those people are unavailable, or when a framework updates, the cracks show quickly.
When Three Frameworks Speak Three Different Languages
A data processing record under GDPR is not the same artefact as an information asset register under ISO 27001, even though both document how personal data moves through an organisation. A high-risk AI system under the EU AI Act may also be a significant system under internal ISO-aligned risk frameworks, but the classification criteria differ.
The translation work required across all three frameworks is:
- Invisible in project planning and resourcing conversations
- Entirely dependent on individuals who hold the cross-framework knowledge
- Impossible to automate with traditional document management tooling
- A source of audit exposure when those individuals are unavailable
Why Static Document Libraries Are No Longer Sufficient
The instinct is to build a comprehensive document repository, a single source of truth that everyone can search. In practice, these repositories become outdated within months. Policies drift from the controls they reference. Framework updates invalidate assumptions baked into existing documents. New systems are deployed without corresponding documentation updates.
A static library answers the question "where is the document?" A RAG-powered agent answers the question "what does the documentation tell me about this specific obligation, right now?"
The Version Control Problem Nobody Talks About
Version control in compliance contexts is rarely a technical failure. It is an organisational one. Documents are updated by different teams on different schedules, with no automated mechanism to flag when a downstream dependency has changed.
A GDPR data protection impact assessment written two years ago may reference a data transfer mechanism that has since been revised. Nobody flagged it. The document still exists, still looks current, and still gets cited in audits.
What Is a RAG-Powered Agent and How Does It Work?
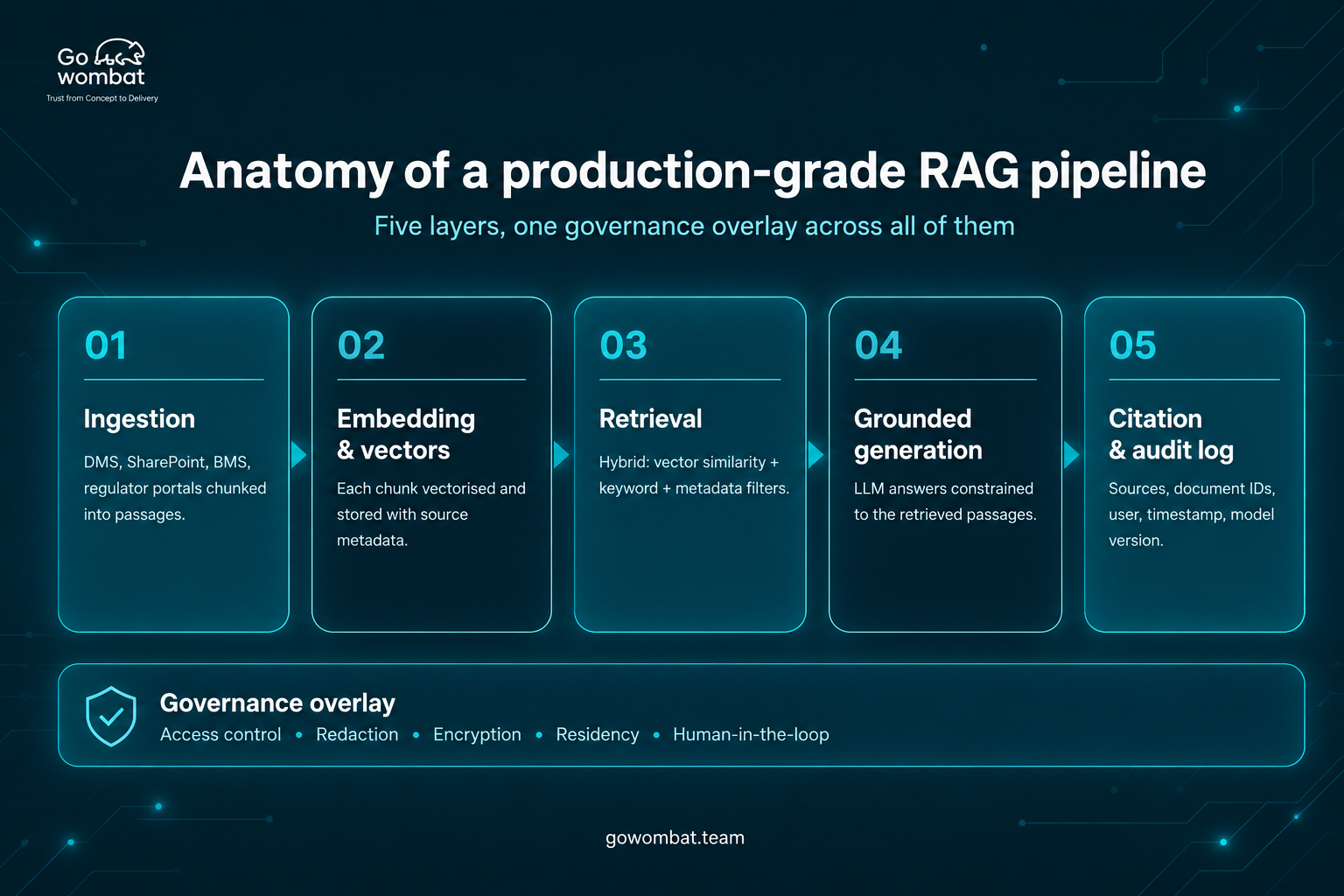
Retrieval-augmented generation is an architecture that connects a large language model to an external, version-controlled knowledge base. Rather than relying on what the model learned during training, the system retrieves relevant content in real time before generating a response.
The core components of a RAG-powered agent in a compliance context are:
- A curated knowledge base containing all relevant policy documents, framework texts, and internal procedures
- A retrieval mechanism that identifies and surfaces the most semantically relevant content for any given query
- A language model that synthesises a response grounded in the retrieved content rather than in generalised training knowledge
- An agent layer that can initiate follow-on actions based on what the retrieval surfaces
That agent layer is what separates a RAG-powered agent from a sophisticated search tool. Rather than simply answering a question, it can flag a gap in documentation, route a query to the correct policy owner, or trigger a review workflow when a retrieved document is past its scheduled review date.
The Difference Between Searching Documents and Retrieving Meaning
Standard enterprise search returns documents that contain matching terms. It is proximity-based. The document with the most keyword matches surfaces first, regardless of whether it actually answers the question.
LLM document retrieval works differently. The system understands semantic intent. Ask whether a particular data transfer to a US-based processor is compliant, and the agent does not return every document mentioning "processor" and "transfer." It identifies the applicable GDPR transfer mechanism, retrieves the relevant processor agreement, checks whether the transfer is documented under the correct legal basis, and surfaces the gap if it is not.
That shift, from locating documents to understanding what they mean in context, is what makes a RAG-powered agent useful across multiple compliance frameworks at the same time.
How Morgan Stanley Used RAG to Unlock 350,000 Documents
The practical distance between document search and intelligent retrieval becomes measurable when you look at what Morgan Stanley built. The firm's wealth management division was sitting on a proprietary research library of over 350,000 documents, spanning decades of institutional knowledge across asset classes, sectors, and regions. Financial advisors needed answers from that library during client conversations, not thirty minutes after them. Manual search was the only option available, and it was consistently too slow.
In 2023, Morgan Stanley partnered with OpenAI to deploy a RAG-powered assistant that indexed the entire library and made it queryable in seconds. The system retrieved relevant documents, synthesised the applicable content, and surfaced answers grounded in named source material rather than model inference. Document retrieval efficiency rose from 20% to 80%. By the time the firm expanded the tool to its institutional securities division in late 2024, 98% of financial advisor teams had adopted it as a daily working tool. The firm's Head of Firmwide AI described the system as making every advisor as knowledgeable as the most informed person in the organisation. That outcome was not a function of the model's training. It was a function of what the retrieval layer could find, and how reliably it could find it.
How Does AI ISO Compliance Change With an Agent?

ISO standards are fundamentally evidence-based. ISO 27001 defines a set of information security controls. Organisations must document how each is implemented, maintain the evidence, and demonstrate continuous effectiveness during audits. ISO 9001 applies the same logic to quality management.
The operational burden is in the assembly. Before an audit, compliance teams typically spend days pulling together evidence packs: locating the right policy version, confirming it maps to the correct control, and checking that supporting records exist and are dated appropriately.
An agent configured for AI ISO compliance changes that process in concrete ways:
- It maps each ISO control to the corresponding internal policy document automatically
- It identifies evidence documents linked to each control and checks their review status
- It flags controls where evidence is missing, incomplete, or overdue for update
- It produces a structured evidence summary that can be reviewed before the audit rather than assembled during it
The practical impact becomes clear under audit pressure. A professional services firm preparing for ISO 27001 recertification faced a familiar problem: its control evidence was distributed across four internal systems, maintained by separate teams using inconsistent naming conventions. After connecting a RAG-powered agent to all four repositories with a unified control mapping, what had previously required a two-week manual consolidation was completed in an afternoon. The audit proceeded without a single evidence chase.
How JPMorgan COiN Replaced 360,000 Hours of Compliance Review
The evidence assembly problem is not hypothetical. JPMorgan Chase confronted it directly in 2017 when the bank launched COiN, short for Contract Intelligence, to address a specific and expensive bottleneck. Its legal and compliance teams were spending over 360,000 hours annually reviewing commercial credit agreements, extracting clause attributes, checking for compliance issues, and mapping findings against regulatory requirements. The work was skilled, repetitive, and entirely manual.
COiN used machine learning and image recognition to read 12,000 commercial credit agreements per year, extracting approximately 150 key attributes per contract in seconds rather than weeks. Error rates dropped. Turnaround times collapsed. Legal professionals who had been occupied with routine clause review shifted to higher-value advisory and negotiation work. What COiN demonstrated, and what remains relevant to any organisation building a compliance documentation layer today, is that the retrieval and classification problem is solvable at scale. The constraint was never the volume of contracts. It was the absence of a system that could read them consistently, accurately, and fast enough to be useful.
Where Does GDPR Fit Into the RAG Agent Workflow?

GDPR compliance generates a continuous stream of internal queries. Can this data be shared with a third-party processor in India? Does this marketing campaign rely on a legitimate interest assessment that is still valid? When did the retention schedule for HR records last receive a formal review?
Each question is answerable, but answering it correctly requires locating the right document, confirming its currency, and applying it to the specific situation at hand. Multiplied across a large organisation, that volume of query handling consumes significant compliance and legal capacity.
How the Agent Routes Queries to the Right Policy Documents
The routing logic is not rule-based in the traditional sense. The agent interprets the semantic content of the query and matches it against the knowledge base structurally. The practical result looks like this:
- A question about cross-border data transfers surfaces the transfer mechanism documentation and the relevant processor agreement
- A question about retention retrieves the retention schedule and the legal basis documentation for the relevant data category
- A question about a specific data subject request pulls the applicable procedure and the response timeline obligations under Article 12
GDPR automation at this level does not introduce legal risk. It reduces the risk of human error, inconsistent application, and answers given from memory rather than from current documentation.
What Does the EU AI Act Add to the Compliance Picture?
The EU AI Act introduces a tiered risk classification system that cuts across existing compliance frameworks rather than sitting neatly beside them.
The four classification tiers and their core implications are:
- Unacceptable risk
Systems that are prohibited outright, including social scoring and certain biometric identification applications.
- High risk
Systems listed in Annex III are subject to conformity assessments, technical documentation, human oversight mechanisms, and EU database registration before deployment.
- Limited risk
Systems with specific transparency obligations, including chatbots and certain content generation tools.
- Minimal risk
Systems with no mandatory requirements beyond general product safety obligations.
For organisations operating multiple AI systems, tracking which system falls under which tier, and what documentation each tier requires, is a new and genuinely complex obligation on top of existing frameworks.
A RAG-powered agent configured with the EU AI Act classification criteria and the organisation's AI system register can maintain a live mapping: each system, its assigned risk tier, its documentation status, and any gaps relative to the Act's requirements.
Consider an organisation that has deployed an AI-assisted decision support tool within its HR function. When internal counsel began assessing EU AI Act exposure, cross-referencing the system's technical documentation against Annex III's employment and worker management provisions was not straightforward. A RAG-powered agent connected to both the system documentation and the regulatory text surfaced the relevant provisions, identified three areas where the technical file was incomplete, and flagged a secondary intersection with GDPR's automated decision-making provisions under Article 22.
Where the EU AI Act and GDPR Intersect and Why It Matters
The overlap between the EU AI Act and GDPR is not incidental. Both regulate how AI systems process personal data, make decisions affecting individuals, and document their logic. A high-risk AI system under the Act that also processes personal data will face obligations under both regimes.
Teams managing each framework in isolation are likely to miss those intersections. A RAG-powered agent operating across both knowledge bases surfaces them as a matter of course.
What Meaningful Oversight Looks Like in Practice
Human oversight under the EU AI Act is not a checkbox. The Act requires that high-risk systems be designed so that natural persons can effectively oversee their operation, intervene when necessary, and override outputs. The key documentation requirements for demonstrating that oversight capability are:
- A clear description of the human oversight measures built into the system design
- Evidence that operators and users have been provided with appropriate instructions
- Logging mechanisms that capture system outputs and any human interventions
- A defined process for suspending the system when oversight cannot be maintained
An agent can maintain the linkage between those documentation requirements and the system's current design state continuously, flagging when changes affect previously documented oversight mechanisms.
What Are the Real Limits and How Should Teams Prepare?
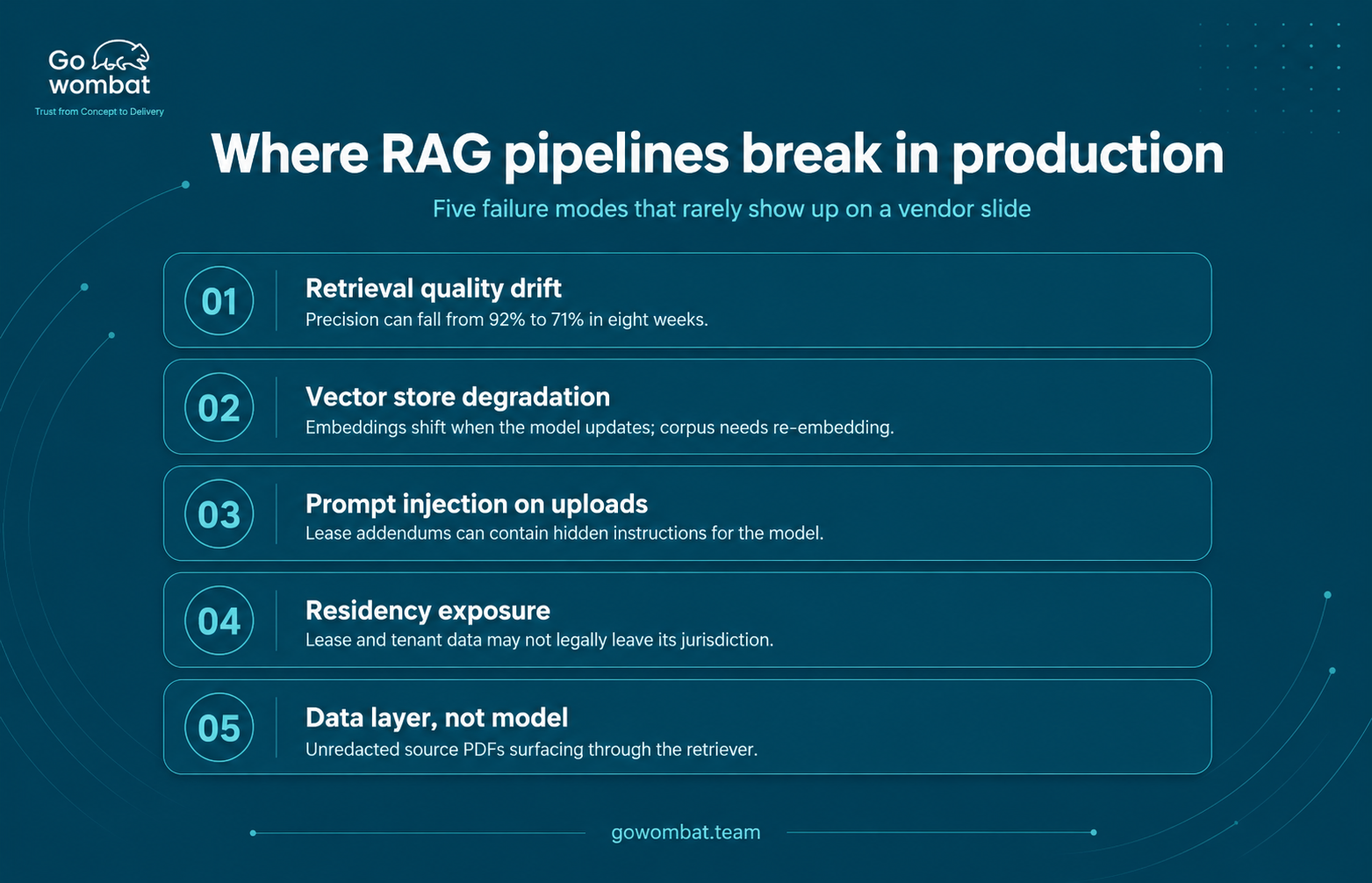
A RAG-powered agent is only as reliable as the documentation it retrieves. If the underlying knowledge base contains outdated policies, incomplete records, or inconsistently structured content, the agent will surface outdated and inconsistent answers with confidence. That is a more insidious problem than a system that visibly fails, because outputs can appear authoritative while being wrong.
The prerequisites for a well-functioning compliance agent are not technical. They are organisational:
- A structured, consistently maintained policy library with clear ownership and review schedules
- Version control discipline across all documents in the knowledge base
- Defined escalation criteria that distinguish queries the agent can resolve autonomously from those requiring human sign-off
- Regular audits of agent outputs against source documents to identify retrieval drift
Designing Human-in-the-Loop as a Feature, Not a Fallback
The appropriate response to these limitations is not to reduce the agent's role, but to design human oversight into the workflow explicitly. Every output that informs a material compliance decision should display its source documents alongside the synthesised answer, so reviewers can verify the reasoning rather than simply accepting the conclusion.
What That Governance Layer Looks Like in Practice
In operational terms, this means defining clear escalation criteria: which query types require human sign-off before action is taken, which can be handled autonomously, and which should trigger a documentation review rather than a direct answer.
A RAG-powered agent deployed with that governance layer in place is a genuinely powerful tool for enterprise AI compliance. Deployed without it, the risks it introduces may outweigh the efficiency gains it delivers.
Final Thoughts
The compliance burden facing enterprise organisations is not a temporary condition. Regulatory frameworks will continue to evolve, intersect, and generate new documentation obligations. The expectation that human teams absorb that complexity without structural support is increasingly difficult to sustain.
What a RAG-powered agent offers is not a shortcut. It is a more intelligent infrastructure for accessing, cross-referencing, and applying compliance knowledge at the speed and scale that modern regulation demands. The retrieval work, the evidence assembly, the routine query handling: these are tasks the technology handles well. The judgment, the accountability, the interpretation of genuinely ambiguous situations: those remain with the people who carry legal and professional responsibility for them.
For organisations navigating ISO frameworks, GDPR, and the EU AI Act at the same time, that division of labour is not a compromise. It is the architecture that makes enterprise AI compliance operationally viable.
Frequently Asked Questions
Can a RAG-powered agent replace a compliance officer?
No. The agent handles retrieval, cross-referencing, and routine query resolution, tasks that consume significant compliance capacity without requiring legal judgment. Decision-making authority over ambiguous or high-stakes matters remains with qualified professionals. The agent reduces the volume of low-complexity work so that compliance officers can focus on work that actually requires their expertise.
How does the agent stay current when regulations change?
The knowledge base must be actively maintained. When the EU AI Act's implementing acts are published, when ISO releases a revised standard, or when GDPR guidance is updated by a supervisory authority, the relevant documentation must be updated accordingly. Some implementations connect to regulatory publication feeds to partially automate this process, but human review of significant changes remains essential.
Is there a risk that the agent produces a confident but incorrect compliance answer?
Yes, and this is the most important limitation to design around. RAG architecture significantly reduces hallucination compared to a model operating from training knowledge alone, because responses are grounded in retrieved documents. However, if the retrieved document is itself outdated or incomplete, the answer may be wrong. Every output used to inform a compliance decision should display its source documents, enabling reviewers to verify the reasoning.
How long does implementation typically take for a multi-framework compliance deployment?
Organisations with well-structured, centralised documentation can typically reach a working proof of concept within six to eight weeks. Full production deployment across ISO, GDPR, and EU AI Act knowledge bases, with routing logic, oversight workflows, and governance controls in place, generally takes between three and six months, depending on the complexity of the existing documentation environment.
Does the EU AI Act apply to the RAG agent itself?
Potentially. If the agent is used in a context the Act classifies as high-risk, for example, supporting decisions that affect individuals' employment, creditworthiness, or access to essential services, the system itself may be subject to the Act's documentation and oversight obligations. This question should be addressed during the design phase with legal counsel familiar with the Act's scope provisions.
Share and subscribe to our blog
Related articles

A Big Step Forward for Our Security: ISO 27001:2022 Certification
Security isn’t just a buzzword at Go Wombat. It’s woven into everything we do from the first line of code to the final sign off on a project. We want our clients to feel confident, not just satisfied. So, today’s announcement means a lot t…

How to Achieve ISO 27001 Certification in 2026?
ISO 27001 certification follows a well defined procedure to demonstrate that your organisation adheres to globally recognised ISO (International Organisation for Standardisation) standards for information security. The certification involv…

6 GDPR Compliance Principles You Need to Master
Organisations may face serious financial, legal, and reputational risk if they do not comprehend and implement GDPR compliance principles. GDPR requirements adherence is a board level concern rather than just legal, technical and organisat…

The Impact of the GDPR on SMEs
How has the law changed since the Data Protection Act, and how does the GDPR affect SMEs? The GDPR concept is not new. We have already touched on it in our and hipaa certification covering some details…

Similarities, Differences, and Everything You Need to Know About GDPR and HIPAA Compliance
If your company leverages digital tools it means that you have to comply with the regulations of the region you work in. For example, if you are gathering, storing, or processing the personal information of European Union (EU) residents, y…

How Can MCP Agents Run a Smart City Grid in Real Time?
How Model Context Protocol agents can coordinate a smart city's energy grid in real time — reading from EMS, DERMS and market feeds, while hard real-time control stays on physical controllers.
-blogCardMobile-480x320.webp)
Is Smart Cities Agentic AI A Missing Infrastructure Layer?
Most smart cities are instrumented, not intelligent. Why agentic AI may be the missing layer that turns sensor data and dashboards into autonomous, real-time action.

How Smart Stadiums Are Evolving into Digital Ecosystems
Smart digital stadiums aren’t just about size or flashy architecture anymore. These days, they’re turning into high tech hubs think AI, IoT, and software development services all working together behind the sce…

How can we help you ?

